Just getting started with LangChain? Here's everything you need to know
Are you just getting started with LangChain? You've come to the right place! This post covers everything you need to know to get started quickly.

Oh LangChain, some love it and some hate it. Whether you're considering adding AI capabilities to your app or working on a new project you must've run into LangChain, the popular LLM framework for Python and Node.js.
What is LangChain?
LangChain is a framework that simplifies integrating LLM capabilities into your application. It supports GPT-4, Gemini, and many other LLMs straight out of the box. LangChain uses chains that are linked together to perform a series of tasks.
LangChain comes with built-in support for various data loaders that can retrieve, organize, and create embeddings for use with LLMs. Data loaders are tools that enable you to extract data into chunks from various sources like PDF files and more.
Do you need LangChain?
So, do you need to use LangChain? Ask yourself the following:
- Comfortable with Python or Node.js?
- Want to add AI capabilities to your app?
- Want to get started with a few lines of code?
- Pressed for time or working within a tight budget?
- Are you OK with including dependencies in your project?
- Need to support custom knowledge? (Chat with your PDF, etc.)
If you answer yes to one or more of the questions above, you'd want to read on because LangChain could be a suitable option for you.
Let's find out!

LangChain alternatives
Of course, LangChain is not the only data framework out there. There are other popular options. Below I'll highlight why you may want to go with LangChan over its alternatives.
Why use LangChain instead of Haystack?
LangChain has more capabilities and supports a broader range of use cases in natural language processing tasks compared to Haystack. It also has greater community support due to its wider developer adoption.
Why use LangChain instead of LlamaIndex?
LangChain is a broader data framework than LlamaIndex and lets you do more by default. It can also integrate with LlamaIndex for search and retrieval capabilities.
Why use LangChain instead of Semantic Kernel?
Semantic Kernel is a great option if you're a C# developer or using the .NET framework. However, LangChain comes with more features out of the box, gets more updates, and you'll find many more resources online if you run into problems due to its wider adoption.
How does LangChain work?
A quick overview of LLMs
Large language models (LLMs) perform language tasks. LLMs can’t generate images or a song but they can complete a sentence or any other request that deals with natural language.
They are stateless, meaning they know nothing about their environment, they have no memory of past conversations and they are trained to generate the next word based on all previous ones. - That's it.
But if LLMs know nothing about the exterior environment how can AI apps like ChatGPT answer questions about your documents? That's where custom knowledge comes in!
Custom knowledge via RAG
Retrieval-augmented generation (or RAG for short) enhances large language models by feeding them extra information they weren't originally trained on. This is especially useful if you're creating an app to interact with specific content, like a PDF or a website.
LangChain helps you augment LLM knowledge and build RAG apps.
Vector Embeddings and Databases
If you have a large document and need specific information from it, you wouldn't paste the whole document and ask the LLM about it. Instead, you only use the parts that are relevant to your question.
This is where vector embeddings and databases come in. Essentially, you transform a document into vectors, then, using fancy mathematical formulas, these vectors are compared with your query for similarity, and only the relevant parts are sent to the LLM.
For example, if we converted your CV into Vector Embeddings and we ran a similarity search using the vector database for the prompt "Where did the candidate study?", just the education section of your CV would be returned.
Prompt engineering
The output of the LLM is as good as the prompt itself. It is very important that you write descriptive and clear prompts that include essential information for the LLM to generate a useful and accurate response.
The choice of words, information, and structure directly impacts the answer generated by the model.
How LangChain talks to LLMs
Now, LangChain comes in and orchestrates the communication between all of these components. Using chains we can index and retrieve data from our vector database. Using another chain, we then send the relevant information from the data to a LLM. You can link many chains together!
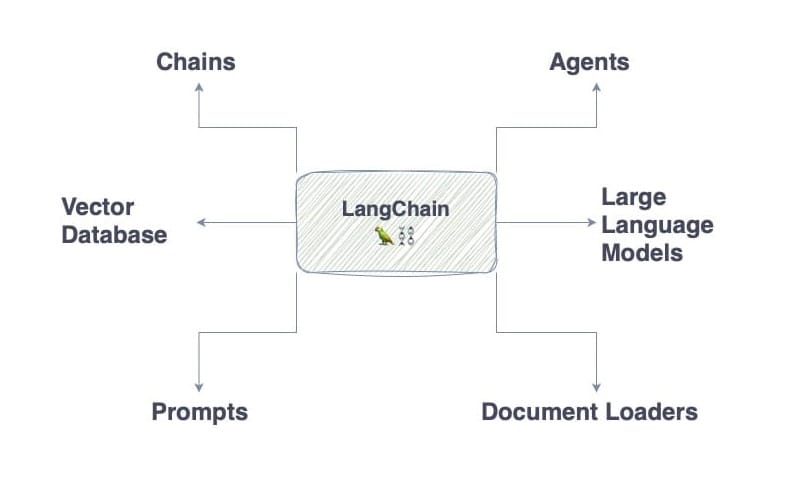
LangChain building blocks
LangChain Chains
A chain in LangChain consists of multiple individual components executed in a specific order, allowing you to combine different language model calls and actions automatically.
LangChain Prompts
A prompt in LangChain is a specific input that is provided to the large language model which is used to generate a response.
LangChain Document Loaders
A document loader in LangChain is an add-on that lets you load documents from different sources, such as PDFs and Word.
LangChain Agents
An agent in LangChain is a type of chain that is capable of choosing which action and tools to use to complete a user input. They are similar to Planners in Semantic Kernel.
Example code using LangChain
The best way to learn and understand how all of this works is by writing code. I've compiled the list below from my previous tutorials so you can get started in no time!
| Title | Description |
|---|---|
| Get started with LangChain using Templates | In this post, I show you how you can use LangChain Templates to quickly get up and running with a starter code for your LangChain app. |
| Give your LangChain app memory | In this post, I show you how to integrate memory in your LangChain app. To keep the answers in context, we need to maintain conversation history since LLMs are stateless. |
| Convert text to SQL using LangChain | In this post, I show you how you can convert your natural language (plain English words) into SQL statements that are then used to query your database. |
| Customize LLM response format using LangChain Output Parsers | In this post, I show you how you can use LangChain to convert LLM output into Pydantic (JSON) objects so that you can easily use them in your app. |
| LangChain and Milvus | In this tutorial, I show you how to integrate LangChain and the Milvus Vector Database to store and retrieve your embeddings. |
| LangChain and Chroma | In this tutorial, I show you how to integrate LangChain and Chroma DB to store and retrieve your embeddings. |
Conclusion
Lots of developers have already built apps using LangChain and many more will. Its wide adoption means great community support and frequent updates.
Before taking the plunge, consider if you need all the features of LangChain or if you're better off building what you need yourself without dependencies. This may require more effort on your part, however, the benefits are increased stability and lower maintenance.
LangChain is a great framework that simplifies the integration of Large Language Models into your application if you're comfortable using Python or Node.js. You can get started quickly thanks to its ability to support a wide range of data loaders, custom knowledge, and more!
Thanks for reading. Please let me know in the comments below if you found the content useful or if you have any questions!
Further readings
More from the Web
More from Getting Started with AI
- All LangChain posts
- What is the difference between fine-tuning and vector embeddings
- What is the Difference Between LlamaIndex and LangChain
- An introduction to RAG tools and frameworks: Haystack, LangChain, and LlamaIndex
- A comparison between OpenAI GPTs and its open-source alternative LangChain OpenGPTs