An introduction to RAG tools and frameworks: Haystack, LangChain, and LlamaIndex
Today, we're going to take a look at Haystack, LangChain, and LlamaIndex and how these tools make it easy for us to build RAG apps.

So you're building the next big thing! It's awesome that you're contributing to the growth of LLM-powered apps and services. In this post, we're going to take a look at three popular tools that enable you to connect your custom data to a Large Language Model, such as GPT-4.
We're going to focus on the following:
STOP! Watch this before you continue reading...
Augmenting LLMs
So why do these tools exist in the first place? As you know, ChatGPT and other LLMs are trained on a set of data up to a certain point in time. More importantly, they do not have access to private information such as documents on your local machine.
Real-world Scenario
You have a 20GB PDF file. You can't simply copy-paste its contents into ChatGPT and expect it to process it. You can't even use the OpenAI API to feed the model 20GB worth of data as there are limitations. In such a case, we could create a numerical representation of the data (called Vector Embeddings), and store it in a vector database. Then based on a given query, we would look up the related information from the vector database and provide it plus the original query to the model as context.
RAG and Vector Embeddings
Retrieval-Augmented Generation (or RAG) is an architecture used to help large language models like GPT-4 provide better responses by using relevant information from data sources and reducing the chances that an LLM will leak sensitive data, or ‘hallucinate’ incorrect or misleading information.
Vector Embeddings are numerical representations of the data. RAG architectures compare the embeddings of user queries to the embeddings stored in the data source to find similarities. The original user prompt is then appended with relevant context from the knowledge library to form the final augmented prompt. This augmented prompt is then sent to the language model.
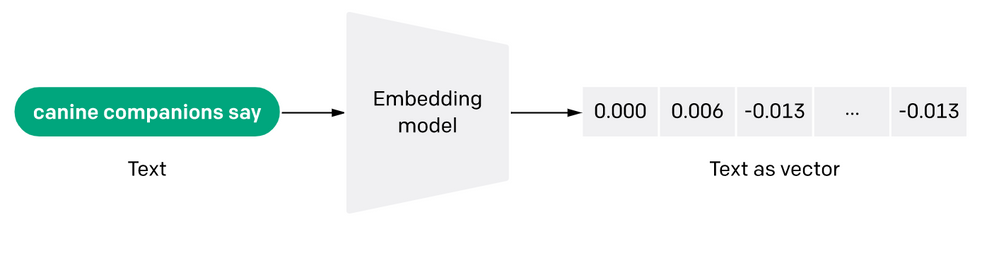
This figure shows how text is transformed into a numerical representation by an Embedding model:
You can read more about Vector Embeddings here:
- From Traditional SQL to Vector Databases In The Age Of AI
- What is the Difference Between Fine-Tuning and Vector Embeddings
We're now going to take a look at some of the most popular tools and frameworks that help us build a RAG app.

Introduction to Haystack
So, what is Haystack? It's an open-source framework for building smart and efficient production-ready LLM applications, retrieval-augmented generative pipelines, and state-of-the-art search systems.
Haystack Key Components
Nodes: Nodes are building blocks that perform specific tasks, such as answering questions or processing text. You can use them to manipulate data directly, which is helpful for testing and experimenting.
Pipelines: You can combine nodes to create more powerful and flexible systems. Pipelines define how data flows from one node to another, allowing you to design complex search processes.
Agent: The Agent is a versatile component that can answer complex questions using a large language model. It uses tools such as Pipelines and Nodes iteratively to find the best answer.
REST API: Haystack also provides a way to deploy your search system as a service that can handle requests from different applications in a production environment.
Introduction to LangChain
From the official docs:
LangChain is a framework for developing applications powered by language models.
LangChain is a framework that enables the development of data-aware and agentic applications. It provides a set of components and off-the-shelf chains that make it easy to work with LLMs (such as GPT). LangChain is suitable for beginners as well as advanced users and is ideal for both simple prototyping and production apps.
LangChain Key Components
LangChain exposes high-level APIs (or components) to work with LLMs by abstracting most of the complexities. These components are relatively simple and easy to use.
Chains: A core concept in LangChain is the "chain". A chain is a representation of multiple chained components such as the PromptTemplate and LLMChain. Here's an example:
prompt_template = "Say this in a funny tone: {sentence}"
prompt = PromptTemplate(template=prompt_template,input_variables=['sentence'])
chain = LLMChain(llm=llm, prompt=prompt)
input = {'sentence': 'AI will take over the world' }
chain.run(input)Memory: Another key component provided by LangChain is Memory support out-of-the-box. You can see how memory works below:
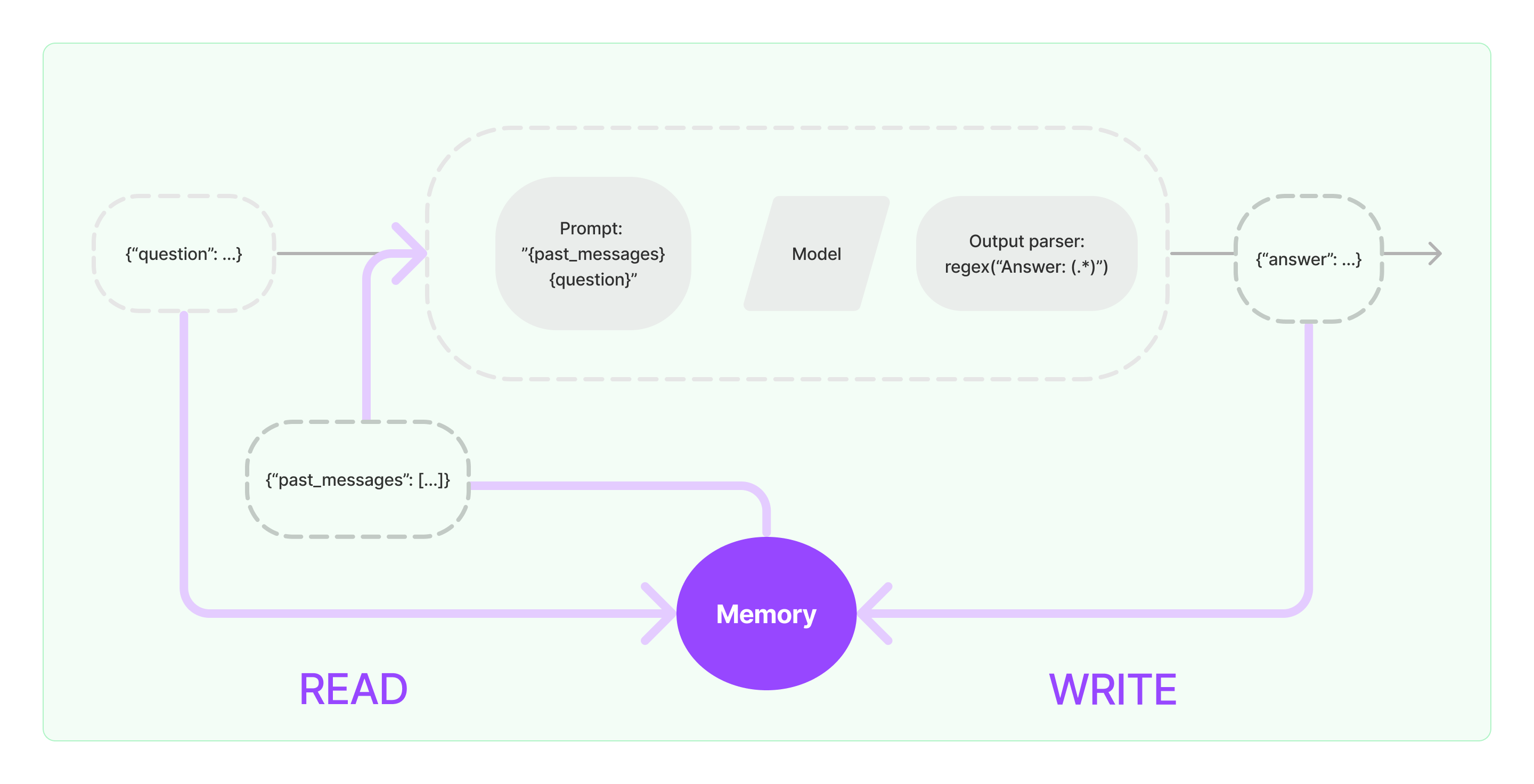
If you'd like to know more about the LangChain Memory component, make sure to check out this post.
Introduction to LlamaIndex
LlamaIndex, (previously known as GPT Index), is a data framework specifically designed for LLM apps. Its primary focus is on ingesting, structuring, and accessing private or domain-specific data. LlamaIndex offers a set of tools that facilitate the integration of private data into LLMs.
LlamaIndex Key Components
LlamaIndex is the optimal tool if you're looking to make use of efficient data indexing and retrieval capabilities. Here are some of its key components:
Data Connectors: Data connectors allow you to ingest data from various sources, including APIs, PDFs, SQL databases, and more. These connectors enable seamless integration of data into the LLM application. There's a large library of available plugins that can integrate with almost anything.
Indices: LlamaIndex structures the ingested data into intermediate representations called Indices that are used to build Query Engines and Chat Engines that enable querying and chatting over ingested data. This ensures efficient and performant access to the data.
Engines: LlamaIndex provides different engines for natural language access to the data. These include query engines for knowledge retrieval, chat engines for conversational interactions, and data agents that augment LLM-powered knowledge workers.
Here's a code sample using LlamaIndex:
query_engine = index.as_query_engine()
response = query_engine.query("Who is the author of Getting Started with AI?")LlamaIndex abstracts it, but it is essentially taking your query "Getting Started with AI?" and comparing it with the most relevant information from your vectorized data (or index), then the similar data and your query are sent out as the final query to the model.
Hubs
Hubs basically are a store of plugins that can extend or tweak the existing capabilities of the tools we covered so far. Here's a list of hub sites for each of them:
Haystack: https://haystack.deepset.ai/integrations
LangChain: https://smith.langchain.com/hub
LlamaIndex + LangChain: https://llamahub.ai
Haystack vs. LangChain vs. LlamaIndex
All three are great tools that allow us to develop RAG apps. You may choose to work with only one of them or a combination of one or more based on your application requirements.
TL;DR: Choosing the Right Framework
Choosing Haystack
Haystack is a framework that provides a set of tools for building scalable LLM-powered applications. It excels at text vectorization and similarity search. One unique feature is its out-of-the-box REST API which can be used to quickly integrate NLP capabilities into mobile or web apps.
Choosing LangChain
LangChain is ideal if you are looking for a broad framework to bring multiple tools together. LangChain is also suitable for building intelligent agents capable of performing multiple tasks simultaneously.
Choosing LlamaIndex
On the other hand, if your main goal is smart search and retrieval, LlamaIndex is a great choice. It excels in indexing and retrieval for LLMs, making it a powerful tool for deep exploration of data.
If I were you...
I would see if my budget and time allow me to build my custom integration. The fewer dependencies, the better. Otherwise, I would go for the tool that most aligns with my project.
Conclusion
Haystack, LangChain, and LlamaIndex provide easy and simple interfaces that enable us to work with Large Language Models and build RAG applications. I suggest you go through the docs of each tool to determine which one works best given your specific use case.
It's important to note that these tools are still relatively new which means that they're constantly going through many changes, updates, and improvements as they mature, so make sure to subscribe (completely free) and follow me on X (Twitter) to stay up to date.
I hope this post was helpful in your learning journey!
Thanks for reading ❤️