Build your next RAG app using Gemini Pro API, LlamaIndex, and Pinecone [Updated for v0.10+]
Let's talk about building a simple RAG app using LlamaIndex, Pinecone, and Google's Gemini Pro model. A step-by-step tutorial if you're just getting started!

Why LlamaIndex, Gemini, and Pinecone? Why not! Some blog members requested that I ditch OpenAI and write about other models, so there you have it.
What we're going to build
For this tutorial, I will show you how to build a simple Python app that uses Gemini Pro, LlamaIndex, and Pinecone to do the following:
- Scrape the contents of this post using
BeautifulSoup - Convert them to Vector Embeddings using
models-embedding-001 - Store the embeddings on a Pinecone index
- Load the Pinecone index and perform a similarity search
- Use LlamaIndex to query the
Gemini Promodel
But wait! Before we get our hands dirty, let's go over the following essential definitions so you know what I'm talking about.
Not a fan of reading? 🤔
Here's a complete video version of this tutorial:
A quick roundup of the basics
What is Google Gemini?
Google Gemini is a multimodal large language model (or LLM) developed by Google DeepMind. It comes in three flavors and understands information across various data types: text, code, audio, image, and video. It's the GPT killer from Google.
What is LlamaIndex?
LlamaIndex is a data framework that helps integrate private data with LLMs to build RAG apps. It offers tools such as data ingestion, indexing, and querying. The framework is available in Python and TypeScript.
What is Pinecone?
Pinecone is a high-performance vector database for machine learning, natural language processing, and computer vision. It offers low-latency vector search and is known for its scalability and ability to handle high-dimensional data.
What is RAG (Retrieval-Augmented Generation)
RAG is a technique that enhances large language models by adding external knowledge, such as information from PDFs or websites (like we're doing today).
The architecture retrieves relevant facts from a data source outside the model's training data, expanding the model's knowledge.
Here's my best attempt at designing a diagram that shows the RAG architecture:
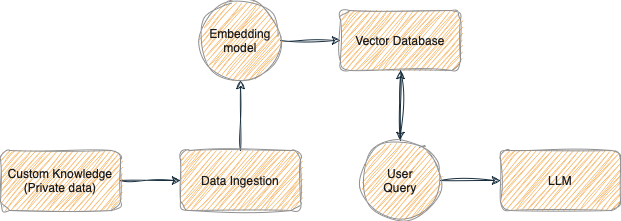
From theory into practice
Great! Now that the boring stuff is out of the way, it's time to get our toolkit and write some code.
We're going to start by creating a free Pinecone account.
How to create a Pinecone index
Let's set up our Pinecone vector database and index. We'll use the index to store and retrieve the data.
Step 1: Create a free Pinecone account
Head over to the Pinecone site and create a free account. Pinecone offers a free tier which is limited to one project and one index.
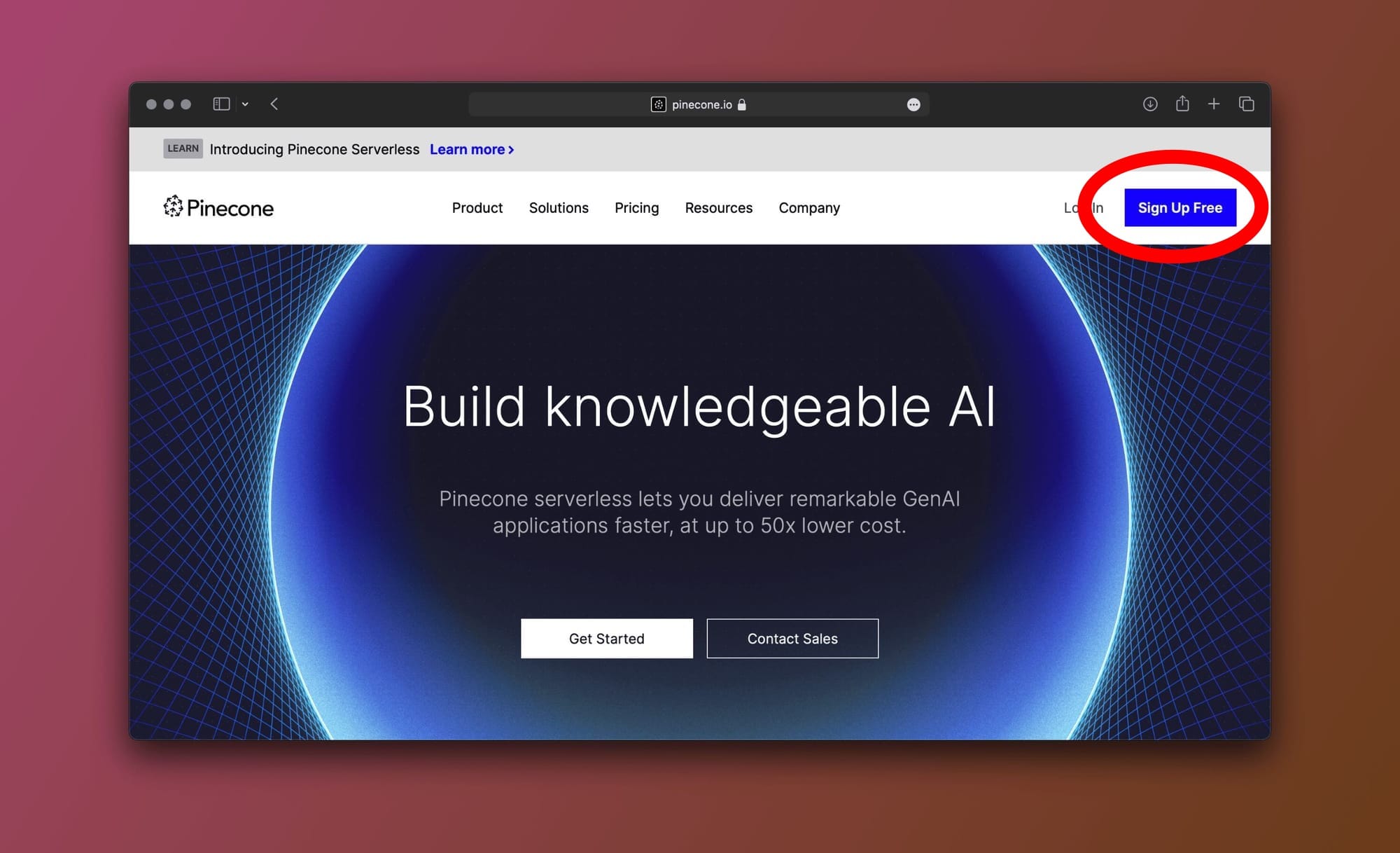
Step 2: Create a Pinecone project
Pinecone automatically creates a starter project for you. We're going to use it to create our index.
To create the index, click on the Indexes tab on the sidebar then click on the Create Index button as shown in the image below:
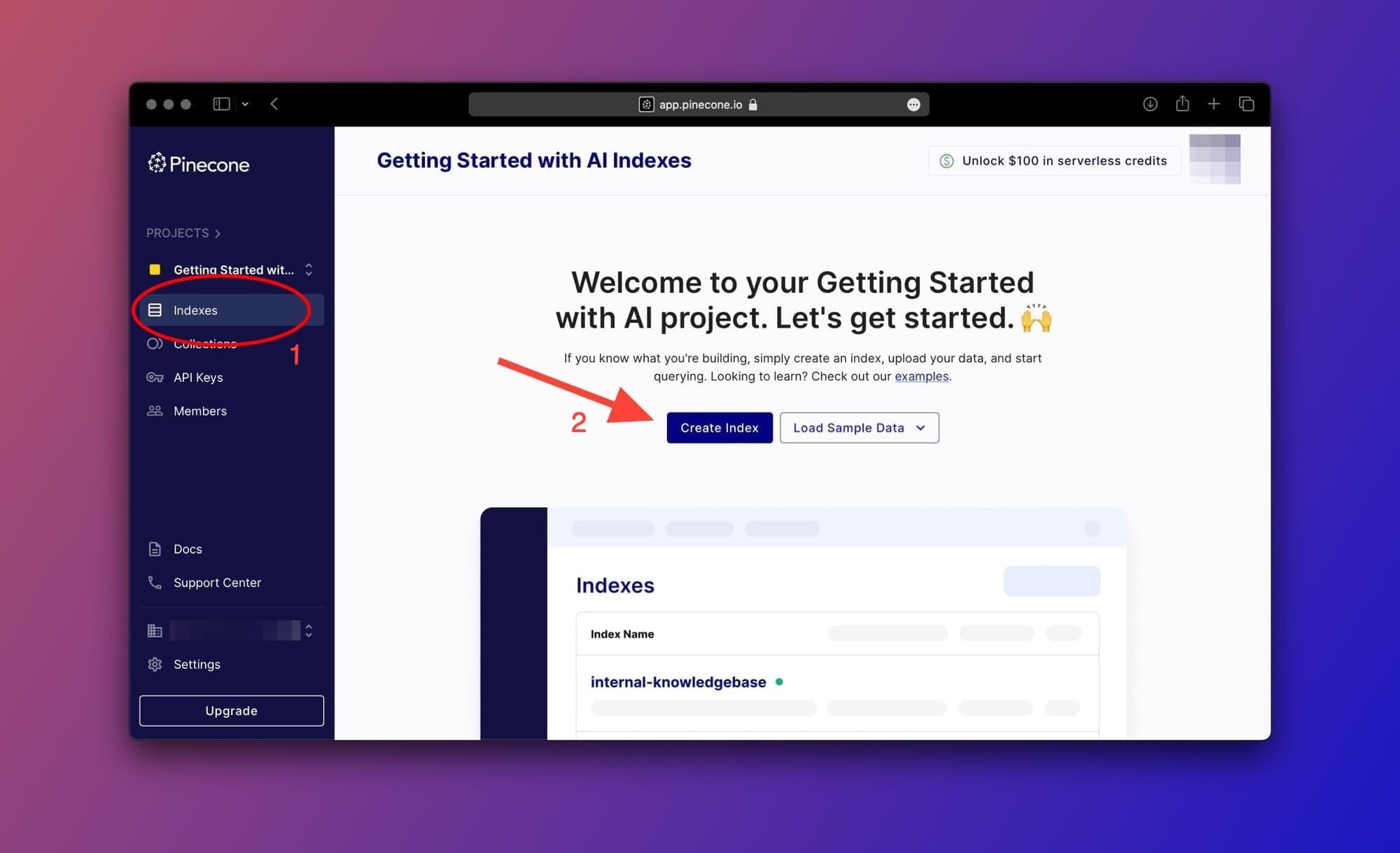
Next, choose any name for the index and make sure to enter 768 as the value for the Dimensions property then choose cosine from the Metric dropdown. You can leave everything else as-is.
Here's what your index configuration should look like:
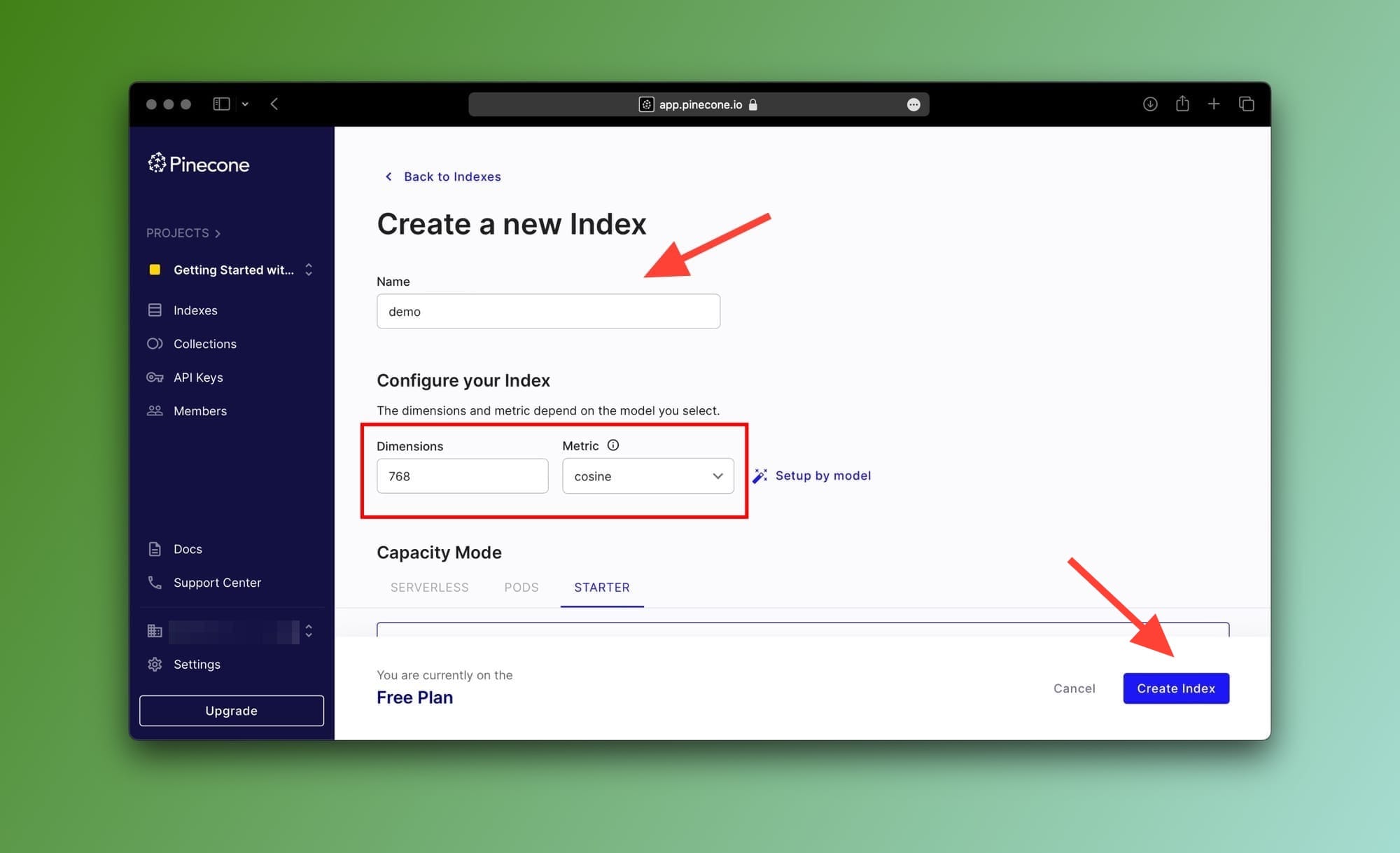
Now, click on the Create Index button to create your first Pinecone index.
create_index method of the Pinecone client and passing the configuration as parameters.Step 3: Grab your Pinecone API key
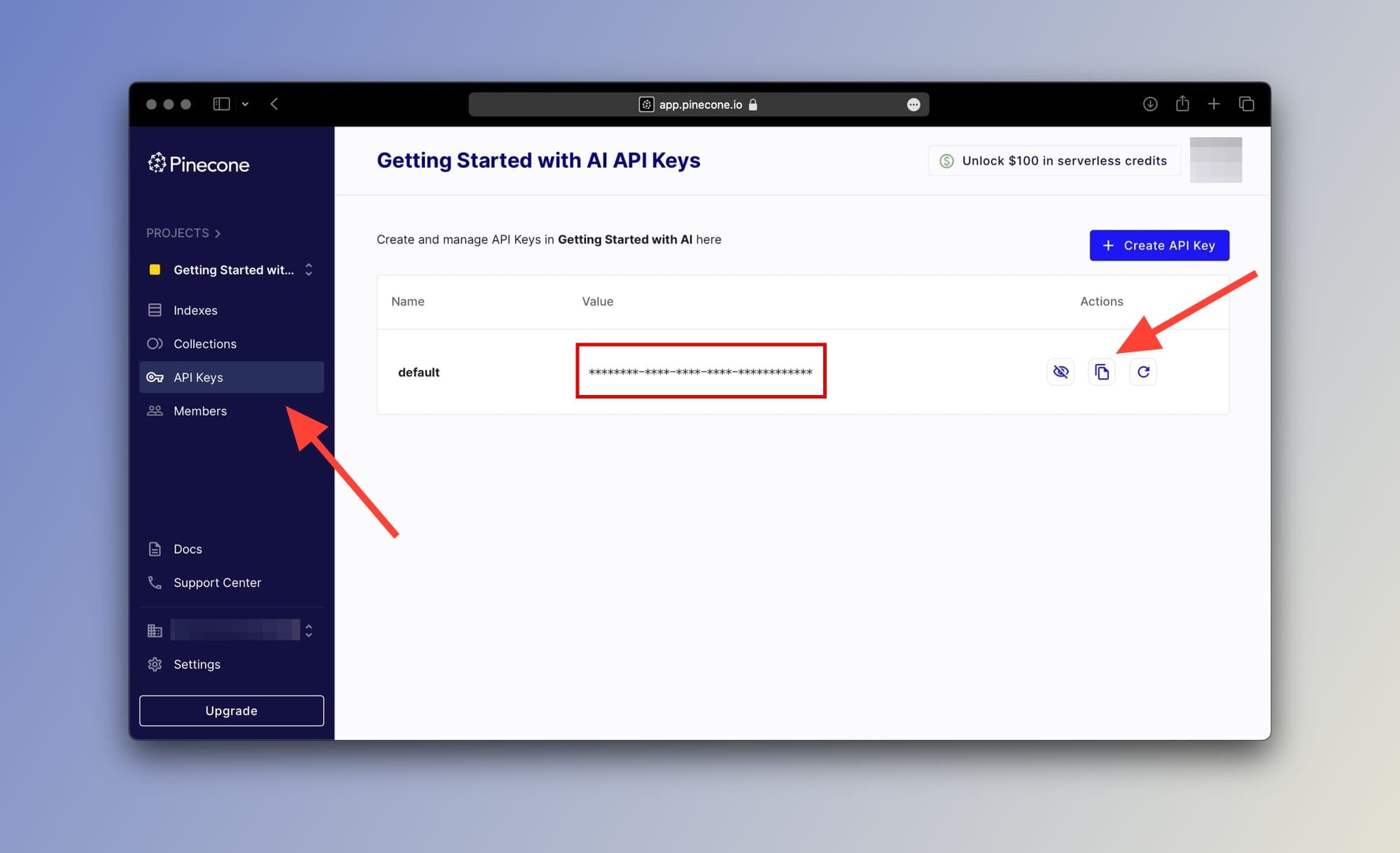
Okay, with our Index set up and ready to go we'll need to grab our API key from the Pinecone console.
Go to the API Keys tab from the sidebar as shown below and copy your key:
How to get a Google Gemini API key
To use Gemini Pro, we need to get an API key from the Google AI Studio. To grab yours, navigate to the Google AI Studio page and log in using your Google account.
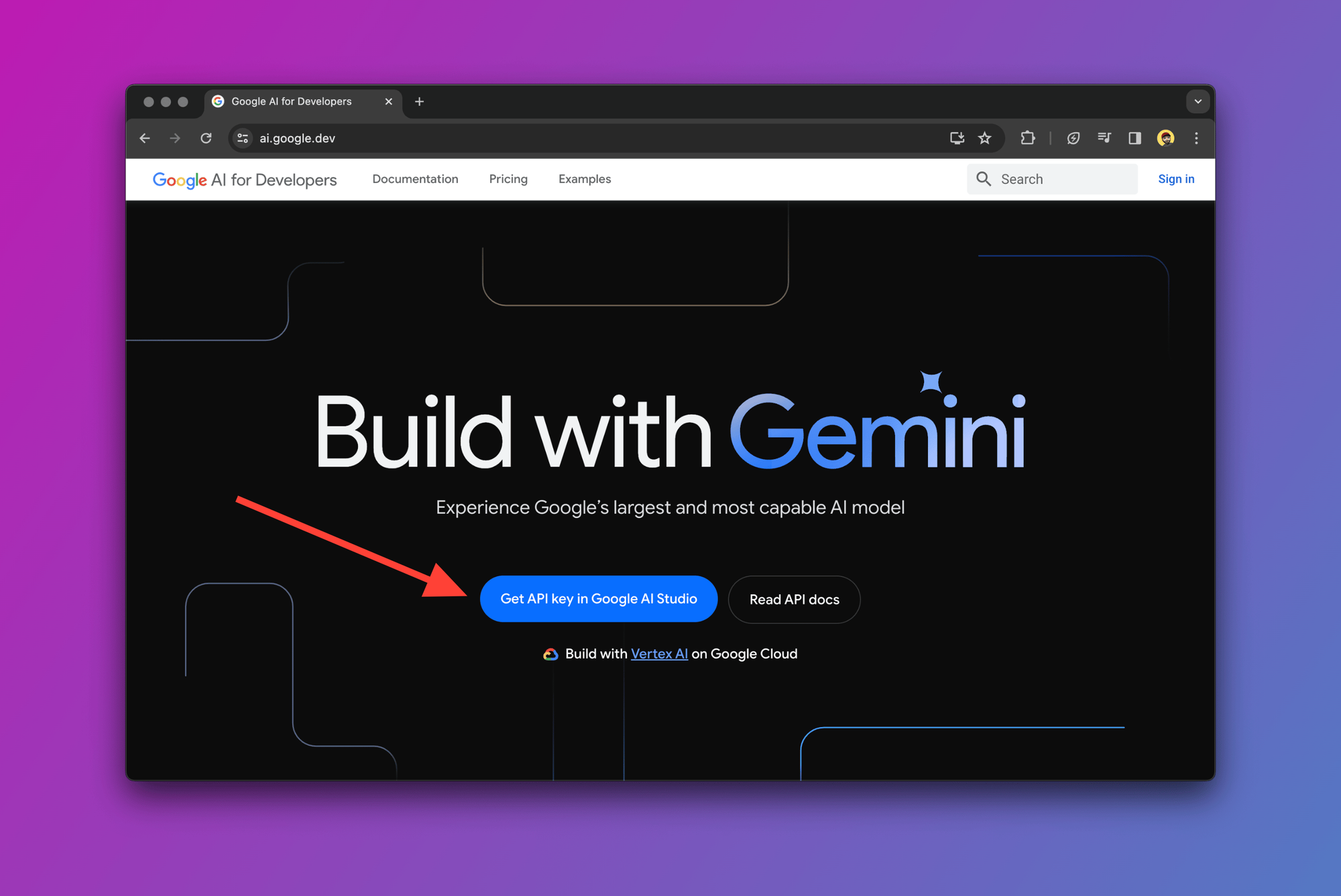
Once inside Google AI Studio, click on Get API key from the sidebar and copy your API key as shown below:
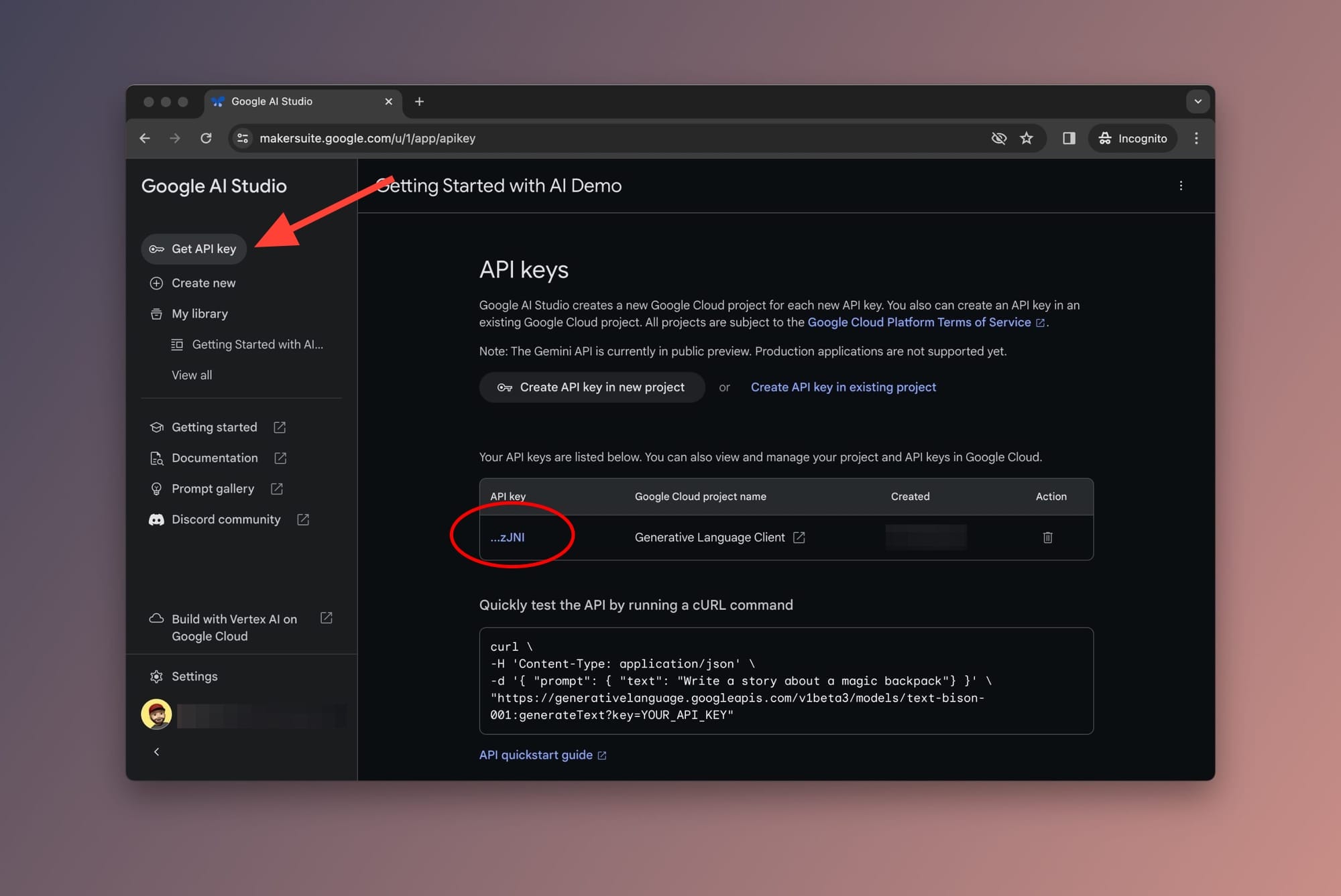
Good! Now we have our Google Gemini API and Pinecone API keys which is all we need to jump to the next part and write some code.
Building a RAG pipeline using LlamaIndex
I'm using a macOS Ventura 13.6.4 but the steps below should be more or less the same for you. In case you run into problems, drop a comment below and I'll try to help.
Step 1: Prepare the environment
Let's create our project directory and our main.py file. In your terminal and from your working directory, type the following commands:
mkdir llamaindex-gemini-pinecone-demo
cd llamaindex-gemini-pinecone-demo
touch main.pyCreating Python directory and main file
Now, let's create and activate a virtual environment. This step is optional, but I highly recommend it. To do so, type the following commands in your terminal:
python -m venv venv
source venv/bin/activateSetting up and activating virtual environment
Next, we'll need to download and install the following packages:
llama-indexBeautifulSoup4google-generativeaipinecone-client
Using pip, type the following command in your terminal:
pip install llama-index BeautifulSoup4 google-generativeai pinecone-clientUsing pip to download and install all packages
For LlamaIndex v0.10+ we need to install the following packages:
llama-index-llms-geminillama-index-embeddings-geminillama-index-vector-stores-pinecone
pip install llama-index-llms-gemini llama-index-embeddings-gemini llama-index-vector-stores-pineconeRequired packages for LlamaIndex v0.10 or later
It may take a few seconds until pip downloads the packages and sets everything up. If all goes well, you should see a success message.
Step 2: Import libraries and define API keys
We'll need to import a few libraries and take care of some basics.
Copy the code below into your main.py file:
For LlamaIndex v0.9.48 or earlier:
import os
from pinecone import Pinecone
from llama_index.llms import Gemini
from llama_index.vector_stores import PineconeVectorStore
from llama_index.storage.storage_context import StorageContext
from llama_index.embeddings import GeminiEmbedding
from llama_index import ServiceContext, VectorStoreIndex, download_loader, set_global_service_contextImporting all required packages for LlamaIndex v0.9.48 and earlier
For LlamaIndex v0.10 or later:
import os
from pinecone import Pinecone
from llama_index.llms.gemini import Gemini
from llama_index.vector_stores.pinecone import PineconeVectorStore
from llama_index.embeddings.gemini import GeminiEmbedding
from llama_index.core import StorageContext, VectorStoreIndex, download_loader
from llama_index.core import SettingsImporting all required packages, assigning default values, and setting Gemini Pro as llm
Set API keys and set Gemini as llm
GOOGLE_API_KEY = "YOUR_GOOGLE_API_KEY"
PINECONE_API_KEY = "YOUR_PINECONE_API_KEY"
os.environ["GOOGLE_API_KEY"] = GOOGLE_API_KEY
os.environ["PINECONE_API_KEY"] = PINECONE_API_KEY
DATA_URL = "https://www.gettingstarted.ai/how-to-use-gemini-pro-api-llamaindex-pinecone-index-to-build-rag-app"
llm = Gemini()Assigning default values, and setting Gemini Pro as llm
Make sure to replace YOUR_GOOGLE_API_KEY and YOUR_PINECONE_API_KEY with your respective API keys that you copied earlier.
If you prefer, you can use the export command to assign your keys to the environment variables like so:
export GOOGLE_API_KEY="YOUR_KEY"
export PINECONE_API_KEY="YOUR_KEY"Setting environment variables using export (Recommended)
Step 3: Create a Pinecone client
To send data back and forth between the app and Pinecone, we'll need to instantiate a Pinecone client. It's a one-liner:
pinecone_client = Pinecone(api_key=os.environ["PINECONE_API_KEY"])Instantiating Pinecone client using the Pinecone API key
Step 4: Select the Pinecone index
Using our Pinecone client, we can select the Index that we previously created and assign it to the variable pinecone_index:
pinecone_index = pinecone_client.Index("demo")Selecting Pinecone index demo
Step 5: Download webpage contents
Next, we'll need to download the contents of this post. To do this, we will use the LlamaIndex BeautifulSoupWebReader data loader:
BeautifulSoupWebReader = download_loader("BeautifulSoupWebReader")
loader = BeautifulSoupWebReader()
documents = loader.load_data(urls=[DATA_URL])Scraping the contents from the provided DATA_URL using the BeautifulSoupWebReader loader
load_data method.Step 6: Generate embeddings using GeminiEmbedding
By default, LlamaIndex assumes you're using OpenAI to generate embeddings. To configure it to use Gemini instead, we need to set up the service context which lets LlamaIndex know which llm and which embedding model to use.
Here's how:
For LlamaIndex v0.9.48 and older:
# Define which embedding model to use "models/embedding-001"
gemini_embed_model = GeminiEmbedding(model_name="models/embedding-001")
# Create a service context using the Gemini LLM and the model
service_context = ServiceContext.from_defaults(llm=llm, embed_model=gemini_embed_model)
# Set the global service context to the created service_context
set_global_service_context(service_context)Setting the global service context to use Gemini and embedding-001 model
set_global_service_context essentially sets the service context as the global default meaning that we will not need to pass it to every step in the LlamaIndex pipeline.For LlamaIndex v0.10 and later:
embed_model = GeminiEmbedding(model_name="models/embedding-001")
Settings.llm = llm
Settings.embed_model = embed_model
Settings.chunk_size = 512Settings now replaces the deprecated ServiceContext in LlamaIndex v0.10+
Step 7: Generate and store embeddings in the Pinecone index
Using the VectorStoreIndex class, LlamaIndex takes care of sending the data chunks to the embedding model and then handles storing the vectorized data into the Pinecone index.
Here's how:
# Create a PineconeVectorStore using the specified pinecone_index
vector_store = PineconeVectorStore(pinecone_index=pinecone_index)
# Create a StorageContext using the created PineconeVectorStore
storage_context = StorageContext.from_defaults(
vector_store=vector_store
)
# Use the chunks of documents and the storage_context to create the index
index = VectorStoreIndex.from_documents(
documents,
storage_context=storage_context
)Upsert Gemini embeddings to the Pinecone index
Alternatively, if you want to load your existing index you can use the from_vector_store method of the VectorStoreIndex class as follows:
index = VectorStoreIndex.from_vector_store(vector_store=vector_store)Loading data from existing vector store
storage_context it contains the vector store information which includes the pinecone_index variable.Step 8: Query Pinecone vector store
Now the contents of the URL are converted to embeddings and stored in the Pinecone index.
Let's perform a similarity search by querying the index:
query_engine = index.as_query_engine()
# Query the index, send the context to Gemini, and wait for the response
gemini_response = query_engine.query("What does the author think about LlamaIndex?")Query the LlamaIndex index and wait for the LLM response
The query_engine uses the query to find similar information from the index. Once it does, the information is passed to the Gemini Pro model, which generates an answer.
Now you've officially built a RAG pipeline using LlamaIndex. Congrats!
Step 9: Print the response
print(gemini_response)Print the response from Google Gemini Pro
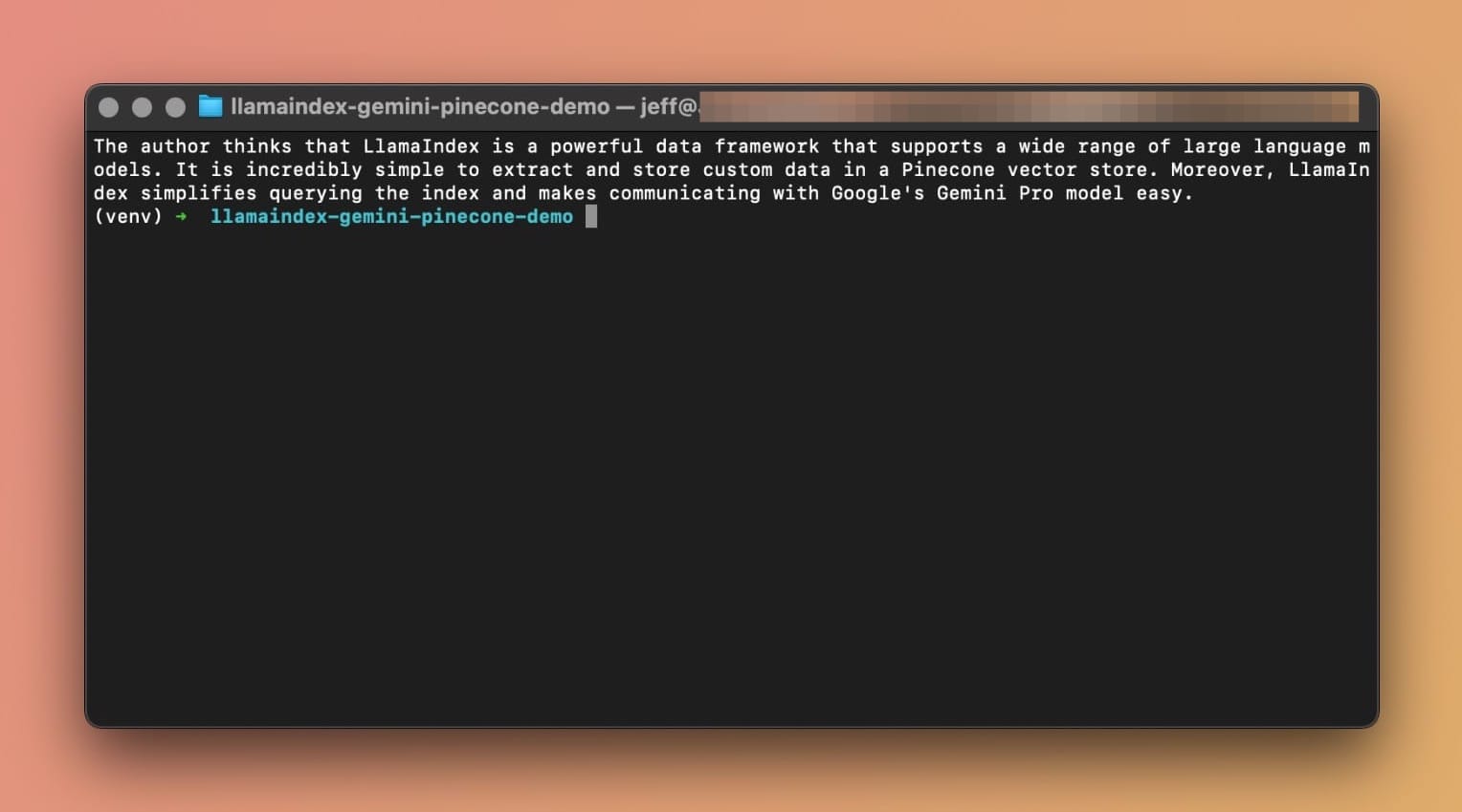
And that's all! Now let's run our Python app. In your terminal window type the following command:
python3 main.pyHere's what Gemini Pro has to say about what I think of LlamaIndex:
The author thinks that LlamaIndex is a powerful data framework that supports a wide range of large language models. It is incredibly simple to extract and store custom data in a Pinecone vector store. Moreover, LlamaIndex simplifies querying the index and makes communicating with Google's Gemini Pro model easy.
python3 main.py
Final thoughts
Beautiful! You made it this far which means you like the content which in turn means that you MUST subscribe to the blog. It's free and you can unsubscribe anytime.
LlamaIndex is a powerful data framework that supports a wide range of large language models. As you've seen, it is incredibly simple to extract and store your custom data in a Pinecone vector store.
Moreover, LlamaIndex simplifies querying your index and makes communicating with Google's Gemini Pro model easy.
If you have any questions, suggestions, or anything else please drop a comment below. Also, follow me on X (Twitter) for more updates.
Further readings
More from Getting Started with AI
- Build Your Own RAG AI Agent with LlamaIndex
- An introduction to RAG tools and frameworks: Haystack, LangChain, and LlamaIndex
- The beginner's guide to start using the new Gemini Pro models in Google AI Studio
- Big news: Gemini the GPT rival from Google DeepMind is finally here
- LlamaIndex: A closer look into storage customization, persisting and loading data
- LlamaIndex: Using data connectors to build a custom ChatGPT for private documents
- Introduction to augmenting LLMs with private data using LlamaIndex
- From traditional SQL to vector databases in the age of artificial intelligence