How to choose the best LLM for your project and evaluate it using LM Studio
Not all LLMs are created equal. With so many options, you should consider important factors to make the right decision for your business. In this post, we’re going to do exactly that!

Are you looking to integrate natural language into your product? Many of us jump straight into OpenAI's arms for our AI needs, however, other LLMs may be a better fit depending on the use case and requirements.
Today, we will go over important factors that you should always consider when choosing an LLM, then, we'll see how to evaluate local models like TinyLlama using LM Studio.
Considerations for choosing an LLM
It's important to understand how the large language model solves your problem so that you can define clear acceptance criteria when evaluating different models.
Start by asking yourself the following:
- Why do I need to use a large language model?
- Is my product going to be used commercially?
- Which specific tasks will be handled by the model?
- What is the frequency of prompts that I need for my project?
- How many tokens will my application use for input/output?
Of course, there are many more questions that you must ask yourself to establish a viable use case for using a LLM. Once you have this cleared up, it's time to carefully evaluate the following key points to avoid any technical and/or business issues that may pop up in the future.
Cost
In most cases, cost is a major deciding factor. Make sure you understand the costs associated with the LLM. You must calculate expected usage to have an idea of running costs for any given LLM.
License
Do you need to use the model for commercial purposes? Make sure you understand the license associated with the model. Some organizations and companies do not allow commercial use or limit it to research only.

Performance
Do you need to process a lot of information quickly? Or is response time not a factor for your product? Not all LLMs process prompts and respond similarly, depending on your requirements you may need an LLM that responds in an acceptable timeframe.
Bias
Has the LLM been evaluated for bias? You must ensure that you understand how the LLM responds to specific prompts and whether it generates misinformation and/or biased answers.
Accuracy
Some LLMs may excel at answering specific prompts but struggle with others. Make sure to evaluate the accuracy of responses based on your use case.
Privacy and security
Are you handling sensitive or private user information? Are you OK with sending user data to LLM providers like OpenAI? Or do you need a self-hosted or local LLM? It's also critical to determine whether the model accidentally reveals any kind of sensitive or proprietary information.
Okay, but how do you evaluate LLMs?
All of the above are deciding factors that you must consider before choosing a LLM for your product.
Hello LM Studio
What is LM Studio?
LM Studio is an easy-to-use desktop app for experimenting and evaluating Large Language Models (LLMs) on your local machine. It lets you compare different models easily.
What is the GGUF file format?
LM Studio uses the GGUF file format which was introduced by the llama.cpp team as a replacement for GGML. It is a format that makes it easy to read and quickly load and save models.
Setting up LM Studio
13.6.4 in System Settings -> General -> Software Update. (I had issues with an earlier macOS version)Step 1: Download and install LM Studio
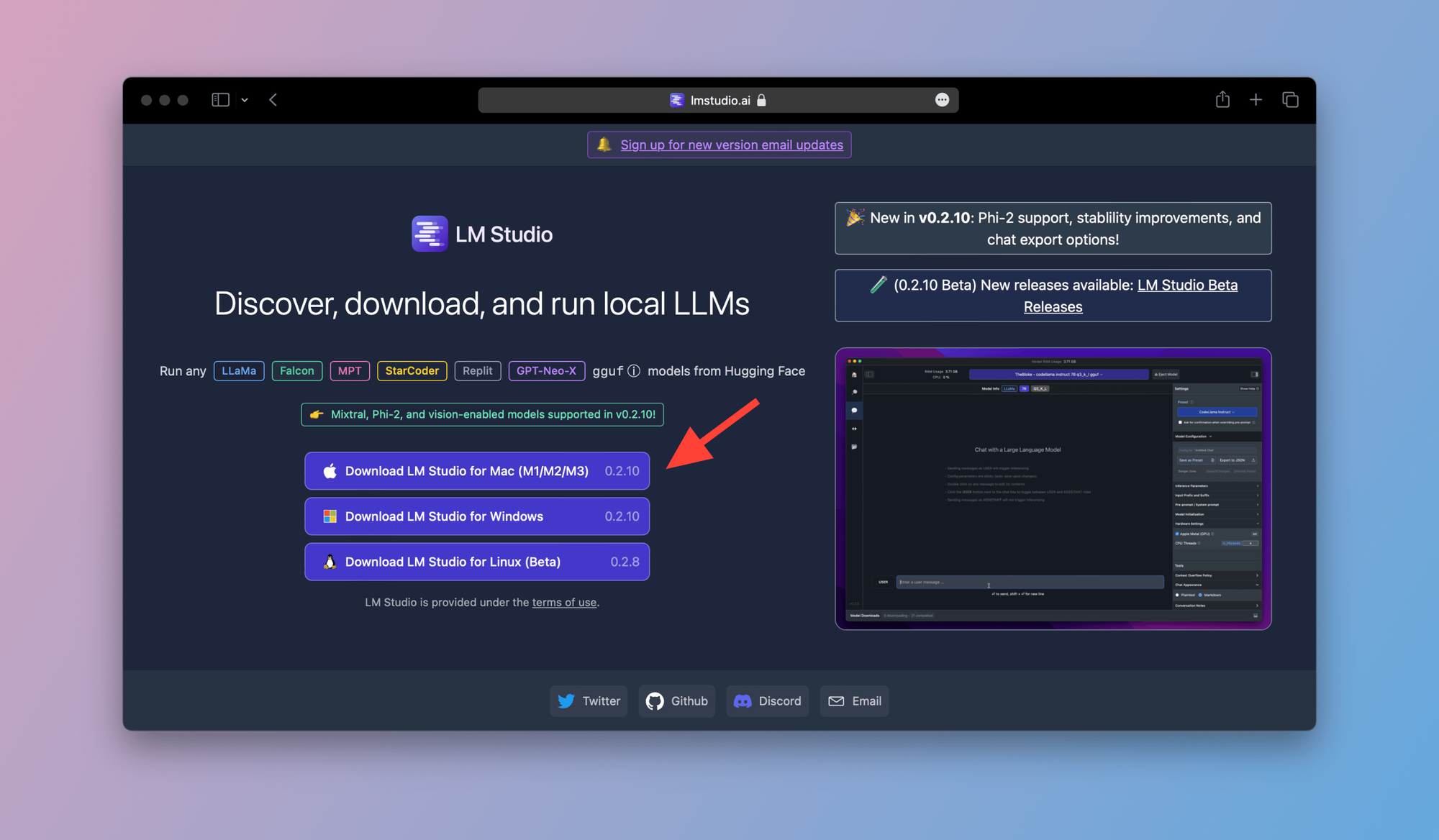
- Head over to the official LM Studio website by clicking on this link.
- Choose your operating system from the options shown below:
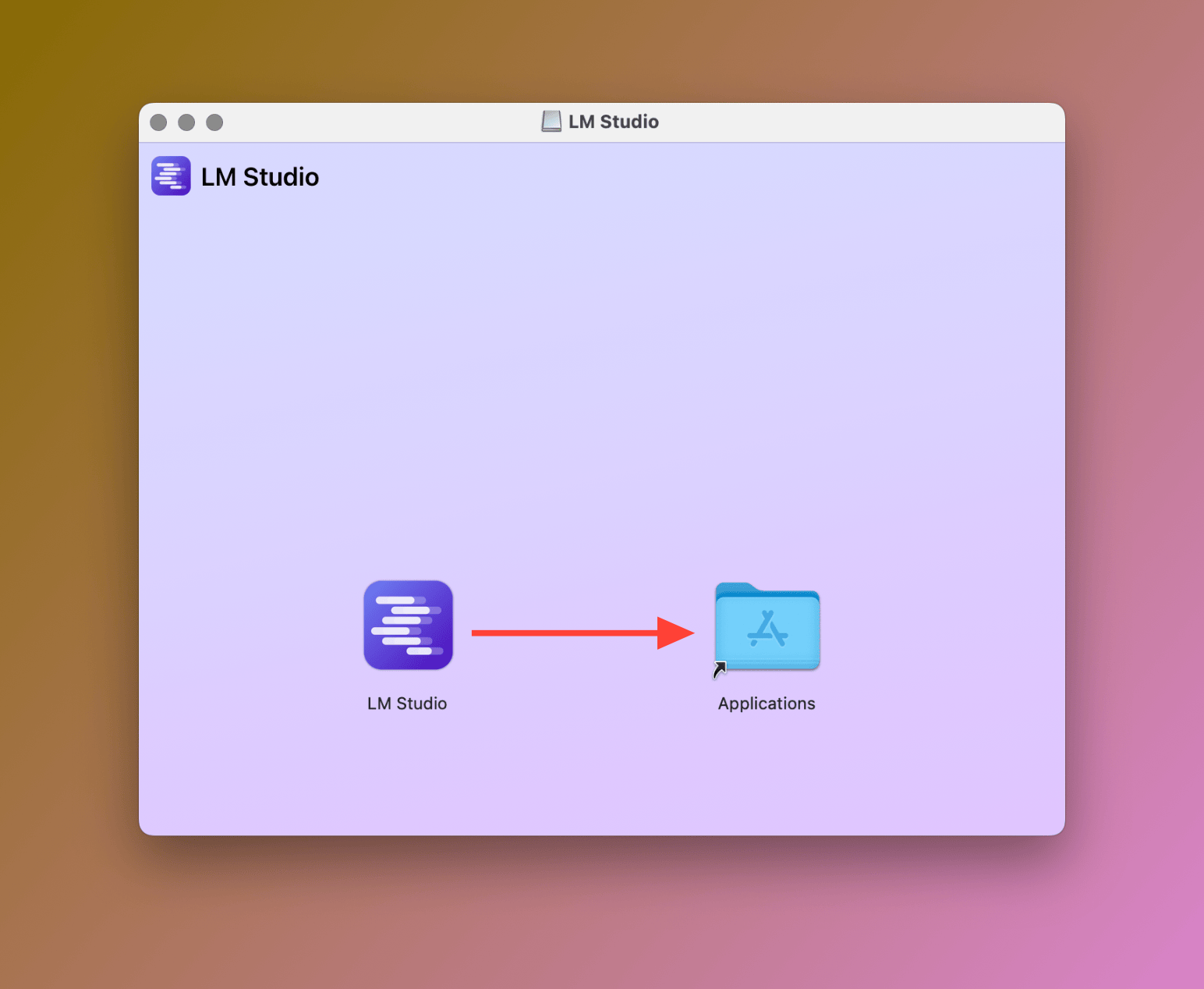
Step 2: Move the LM Studio app to your Applications folder (macOS Only)
Step 3: Launch LM Studio
From your Applications folder, launch LM Studio. You'll see the following welcome screen:
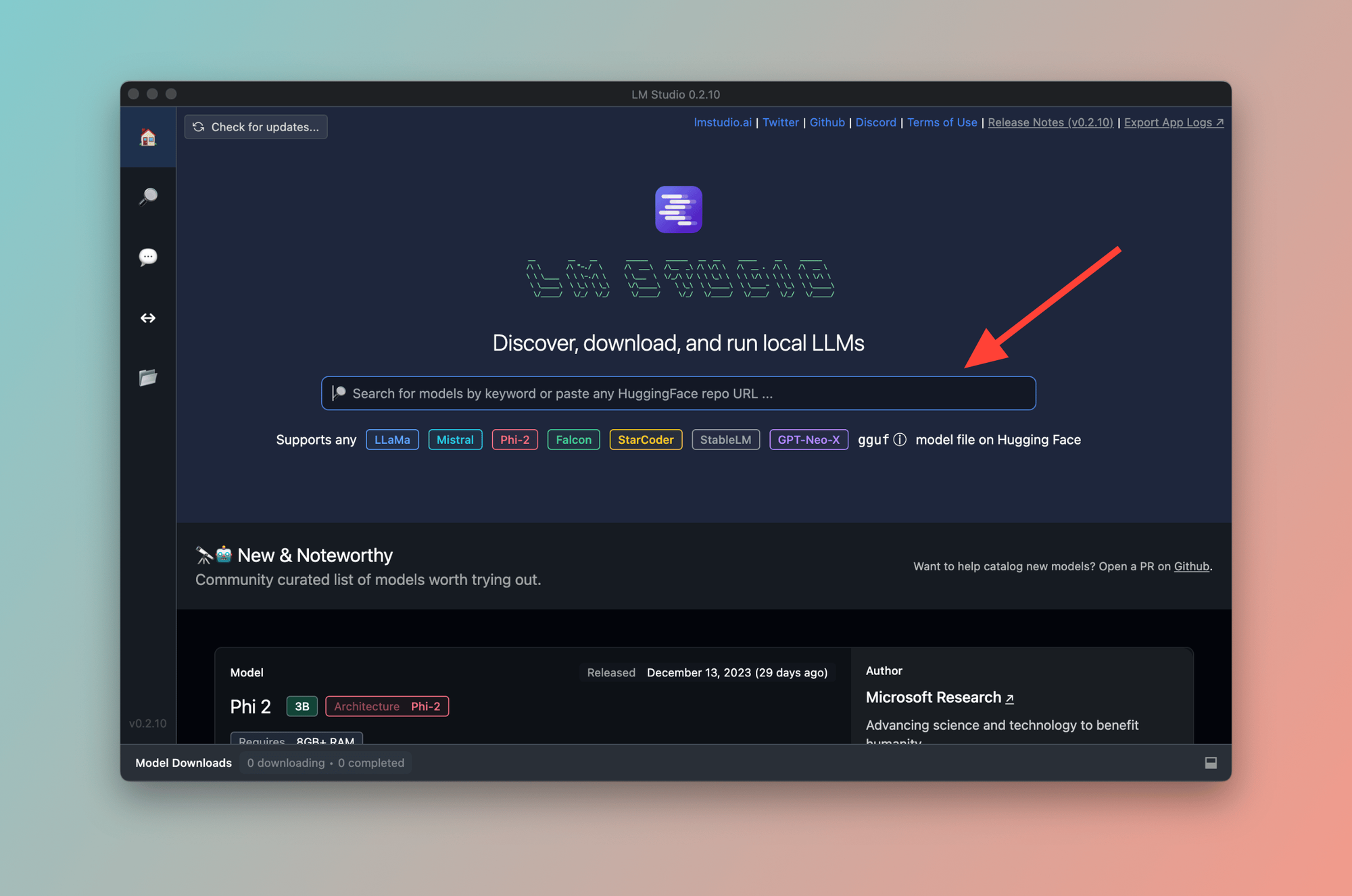
As soon as you open LM Studio, you can see a search bar that lets you look for a model. You can also paste a HuggingFace repo URL in the search box.
Next, we're going to find and install two models.
Step 4: Search for an LLM
In the search box, type "Tiny Llama" and hit return. You should see the same results as shown below:
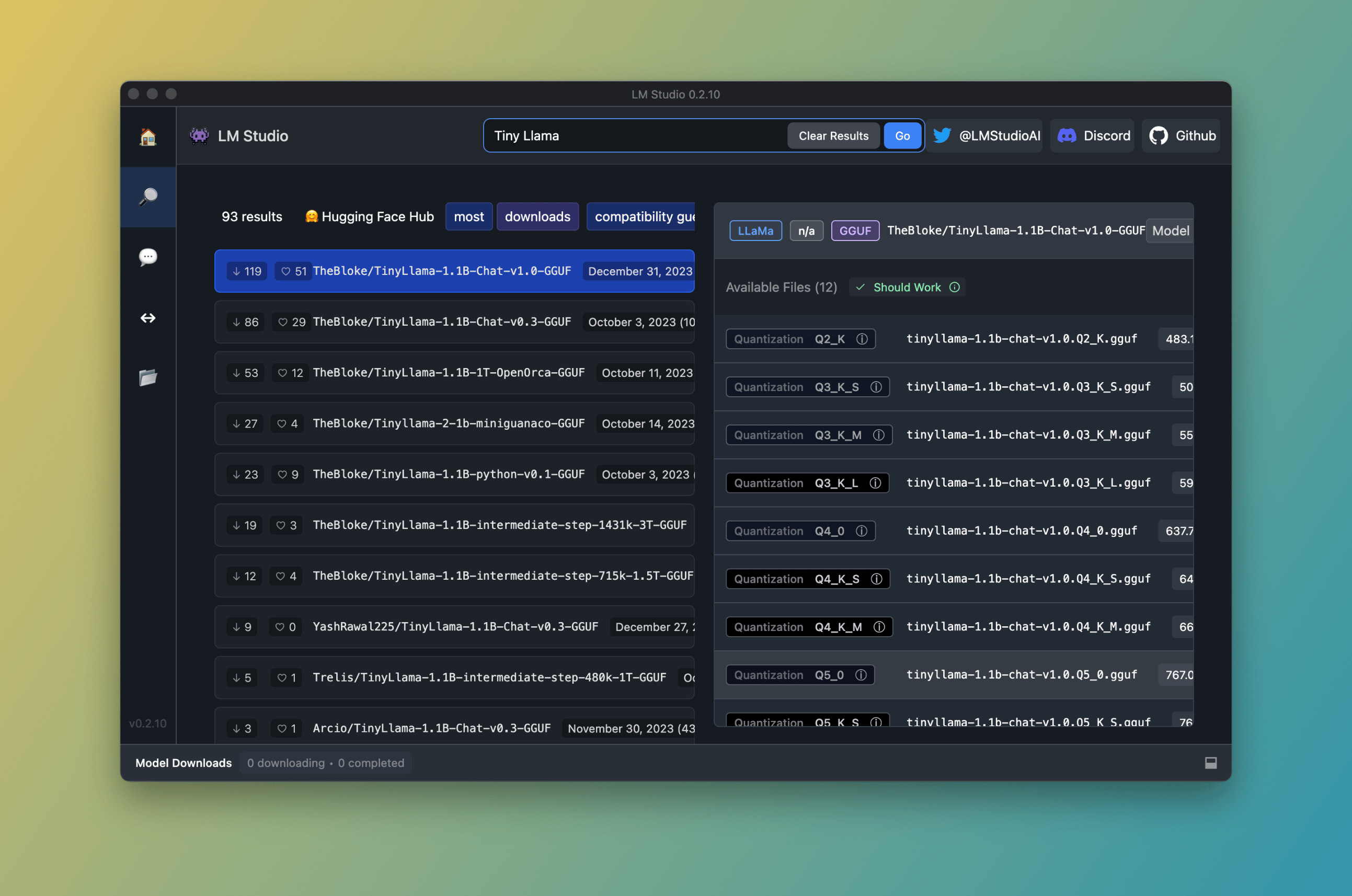
I'm searching for the model TinyLlama since it's a compact model and does not need a lot of computing power to run on my machine.
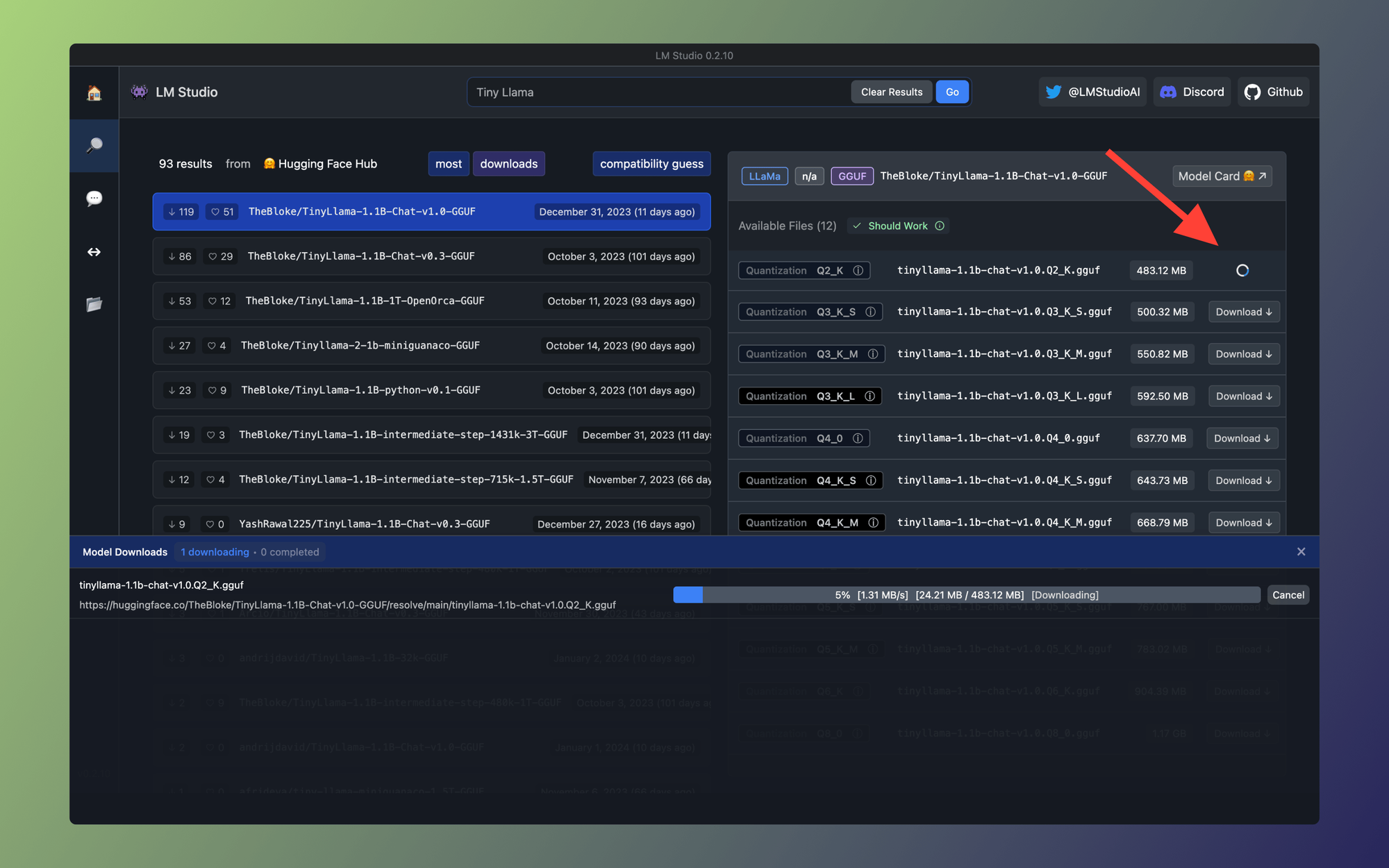
Step 5: Download TinyLlama
Okay, so far so good. Let's download and install TinyLlama. Click on the Download button as shown below:
Step 6: Chat with the model
Beautiful! We have two local models installed and ready to go. Now, we can try them using the Chat UI provided by LM Studio. Let's navigate to the Chat window and ask the model how many letters there are in the English alphabet:
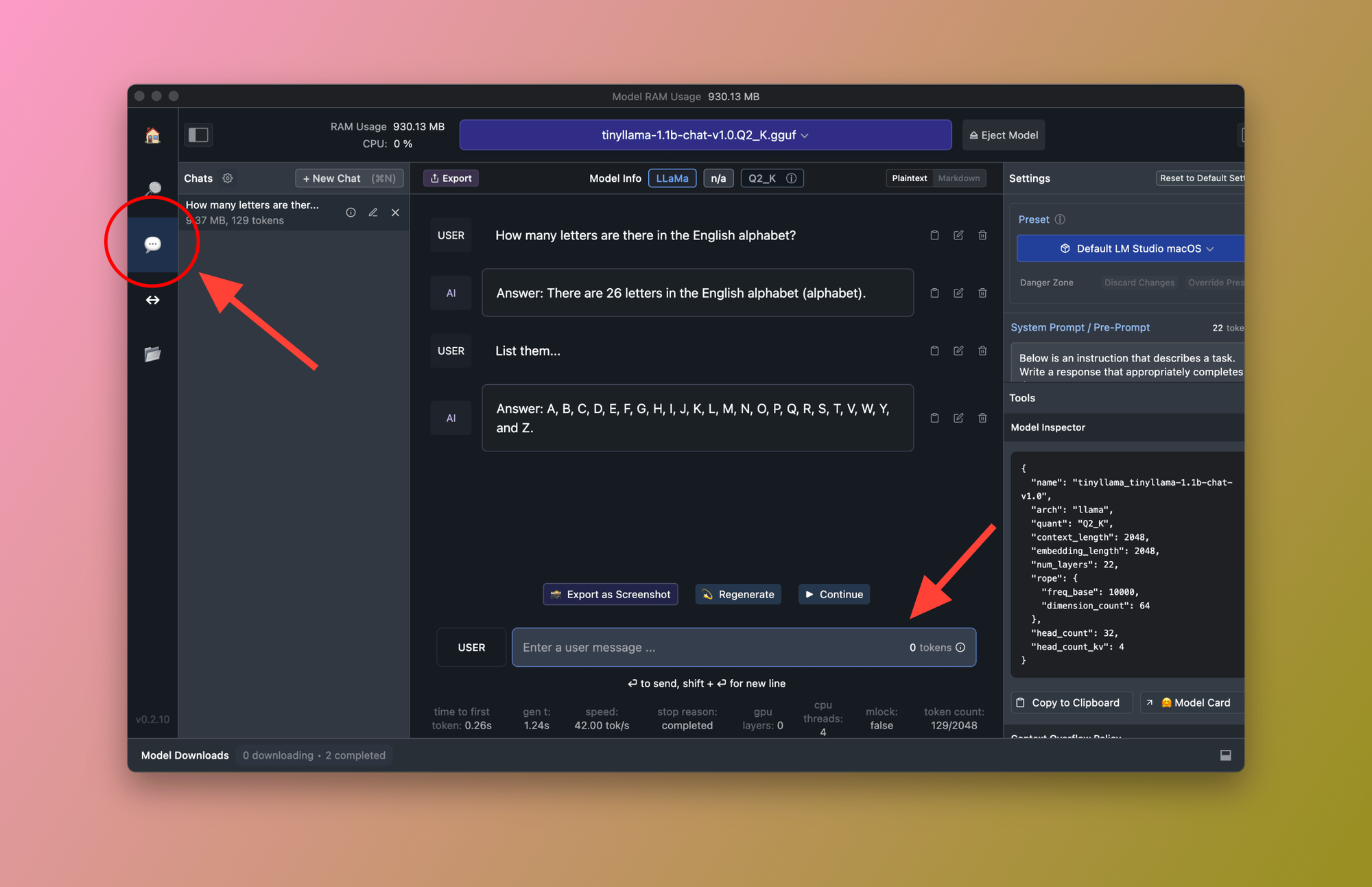
As you can see, in a few minutes, using the Chat UI within LM Studio we can test any locally installed model.
Step 7: Switch between models
The provided Chat UI lets you experiment and validate your chosen LLM. You can switch between models to see how different models respond to the similar prompts. To do so, use the Model Selector dropdown as shown below:
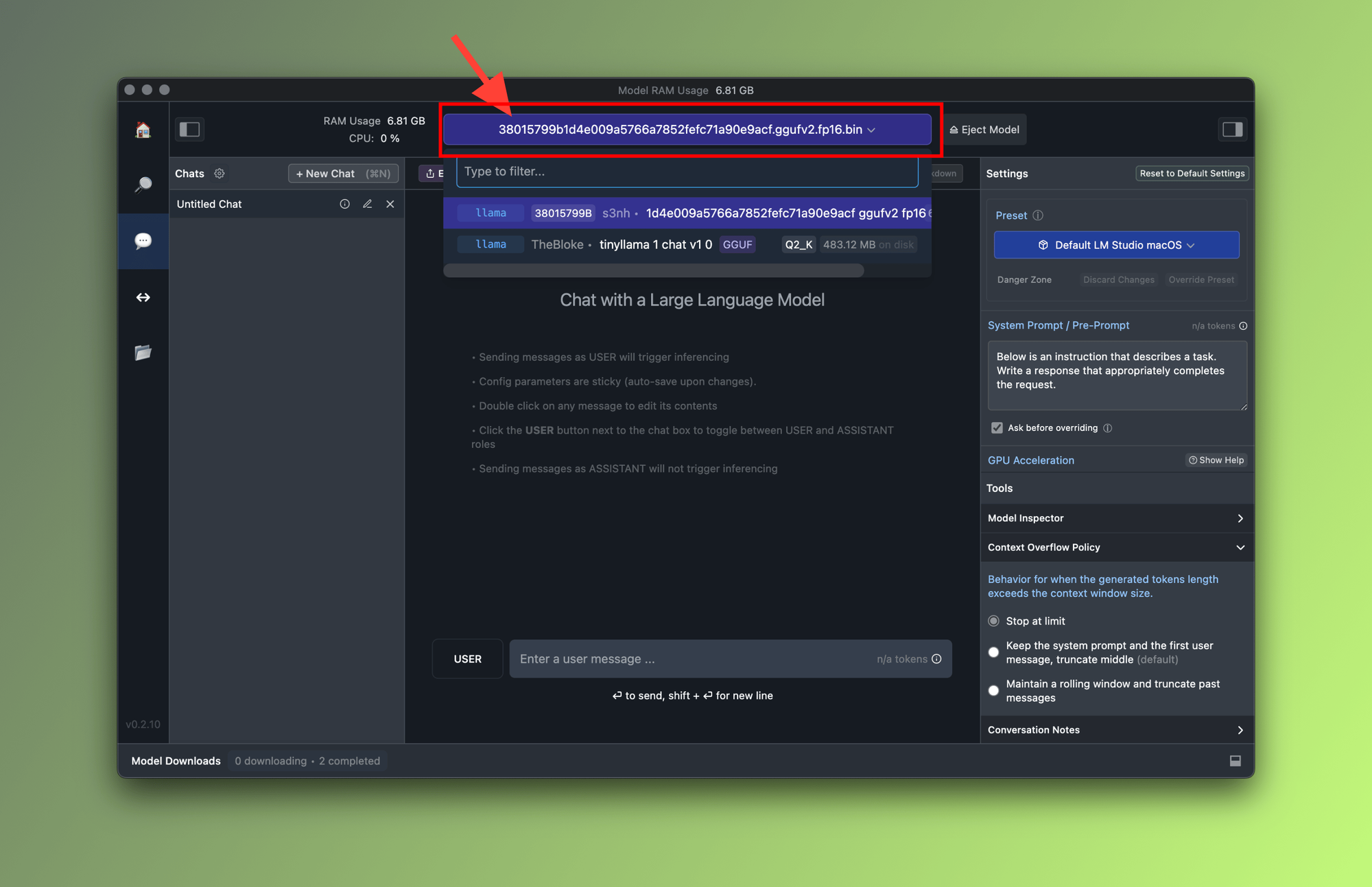
Step 8: Run the model on a local HTTP Server
Another awesome out-of-the-box LM Studio feature is the local HTTP Server. By running a local server, we can directly integrate the model within our application.
To run the server, you'll first need to go to the HTTP Server tab from the main menu and then click on Start Server as shown below:
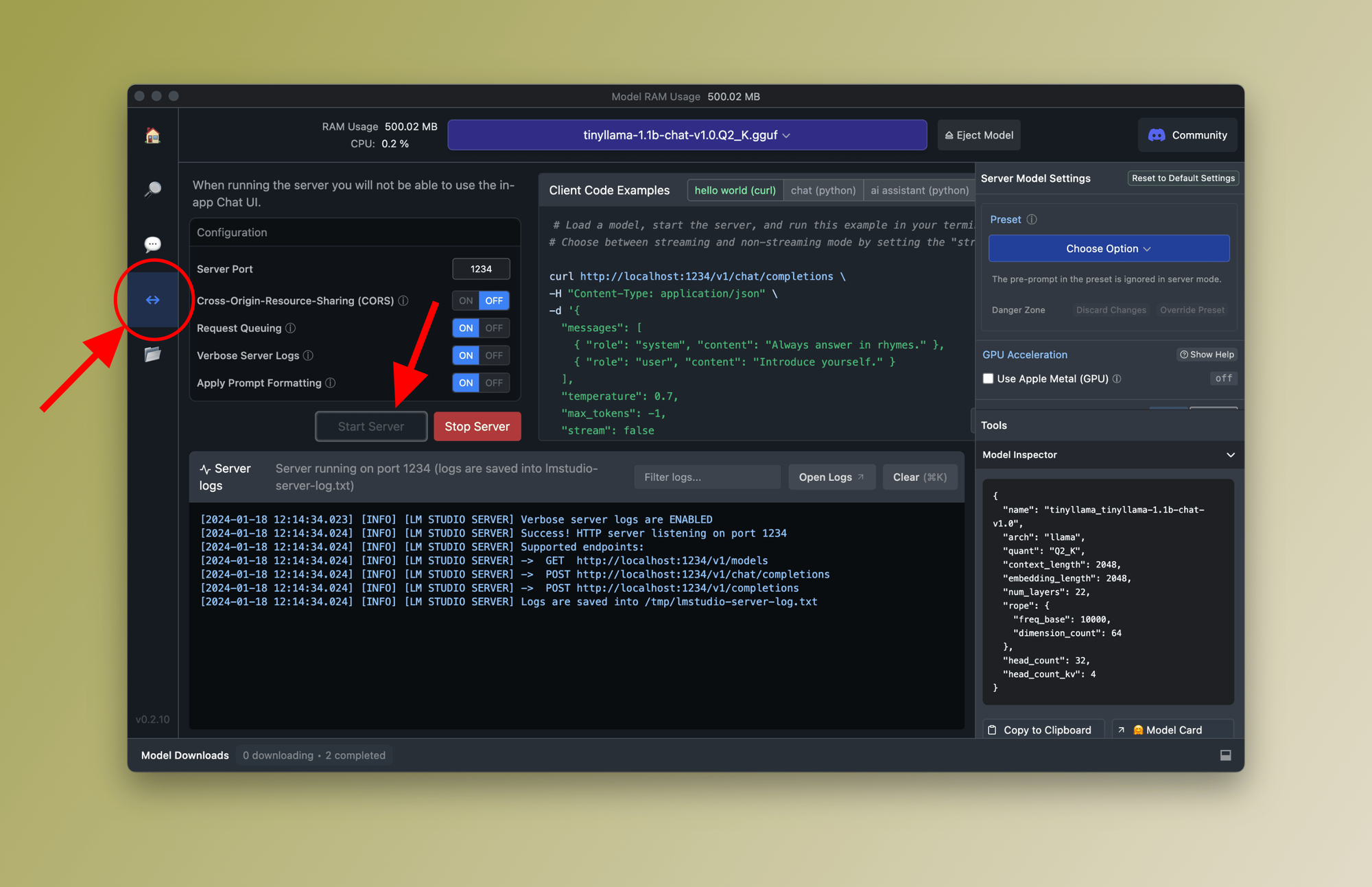
Now the HTTP Server is running on your localhost and using port 1234 (or whichever you manually assigned). As you can see in the logs window, three endpoints are exposed:
http://localhost:1234/v1/modelshttp://localhost:1234/v1/chat/completionshttp://localhost:1234/v1/completions
Look familiar? This is because LM Studio implements OpenAI's endpoints and structure which makes re-using existing OpenAI code easy.
Here's the provided sample code re-using an existing OpenAI setup:
from openai import OpenAI
client = OpenAI(base_url="http://localhost:1234/v1", api_key="not-needed")
completion = client.chat.completions.create(
model="local-model", # Will use selected model (TinyLlama in our case)
messages=[
{"role": "system", "content": "Always answer in rhymes."},
{"role": "user", "content": "Introduce yourself."}
],
temperature=0.7,
)
print(completion.choices[0].message)Python code sample integration LM Studio with local HTTP Server
Final thoughts
Of course, OpenAI's GPT is a great option, but it may not be the best option if you're trying to cut costs, double down on privacy, and eliminate relying on third-party LLM providers.
I highly advise you to perform thorough research to find a list of models that are most closely positioned to perform tasks related to your specific use case, then, as we've seen in this tutorial use LM Studio for a free and quick way to evaluate and test your chosen models before going all in and making a final decision!
Thanks for reading and I hope you found the content helpful in your coding journey. And hey! I want to know what you think so please drop me a comment and let me know if you have questions or suggestions about this post.
I Invite you to become a member (for free) now to get exclusive access to new and upcoming posts, also follow me on X for daily updates and more.
Further readings
More from Getting Started with AI
- How to evaluate GPT via the AI Assistants Chat interface
- How to evaluate Google's Gemini Pro and Pro Vision using Bard
FAQ: Frequently asked questions
Can LM Studio use GPU?
Yes, LM Studio supports NVIDIA/AMD GPUs.
What are the minimum requirements to run LM Studio?
- Apple Silicon Mac (M1/M2/M3) with macOS 13.6 or newer
- Windows / Linux PC with a processor that supports AVX2 (typically newer PCs)
- 16GB+ of RAM is recommended. For PCs, 6GB+ of VRAM is recommended
NVIDIA/AMD GPUs supported
Does LM Studio send data over the Internet?
No, LM Studio is completely running on your machine. Meaning you can use it to evaluate your models offline.
How do I choose a good LLM model?
Choosing a good LLM starts by defining your use case for the model and then evaluating the model for associated costs, performance, accuracy, bias, privacy, and more.